在计算机中,所有的数据在存储和运算时都要使用二进制数0 1表示,同样的,对各种字符在计算机中存储时也要使用二进制数来表示,而具体用哪个数字表示哪个符号,这就叫编码,而这套编码包含的所有字符我们用字符集来表示。
名词解释:
1.内码:计算机使用的缺省编码方式
2.向下兼容:如果A编码兼容B编码,则说明所有B中字符的编码在A中得到了完全一致的保留,A中增加的字符编码不会与B原有编码冲突。
由于各个地区文字不统一以及计算机发展程度,同样,最开始的文字编码也不统一。
一、ASCII:单字节字符编码
跟计算机发展的起源有关,字符集最早的编码方案来自于与ASCII。
该方案起源于1960年代初期,由美国国家标准学会(American National Standard Institute , ANSI )制定,最后完善成为美国的国家标准ASCII(American Standard Codefor Information Interchange),之后进一步演变成世界性的计算机字符编码标准ISO646(其全名为7-bit coded character set for information interchange)。成为计算机编码方案的基础。
ASCII 码使用指定的7位或8位二进制数组合来表示128或256种可能的字符。
下图为标准ASCII表,以及扩展ASCII表
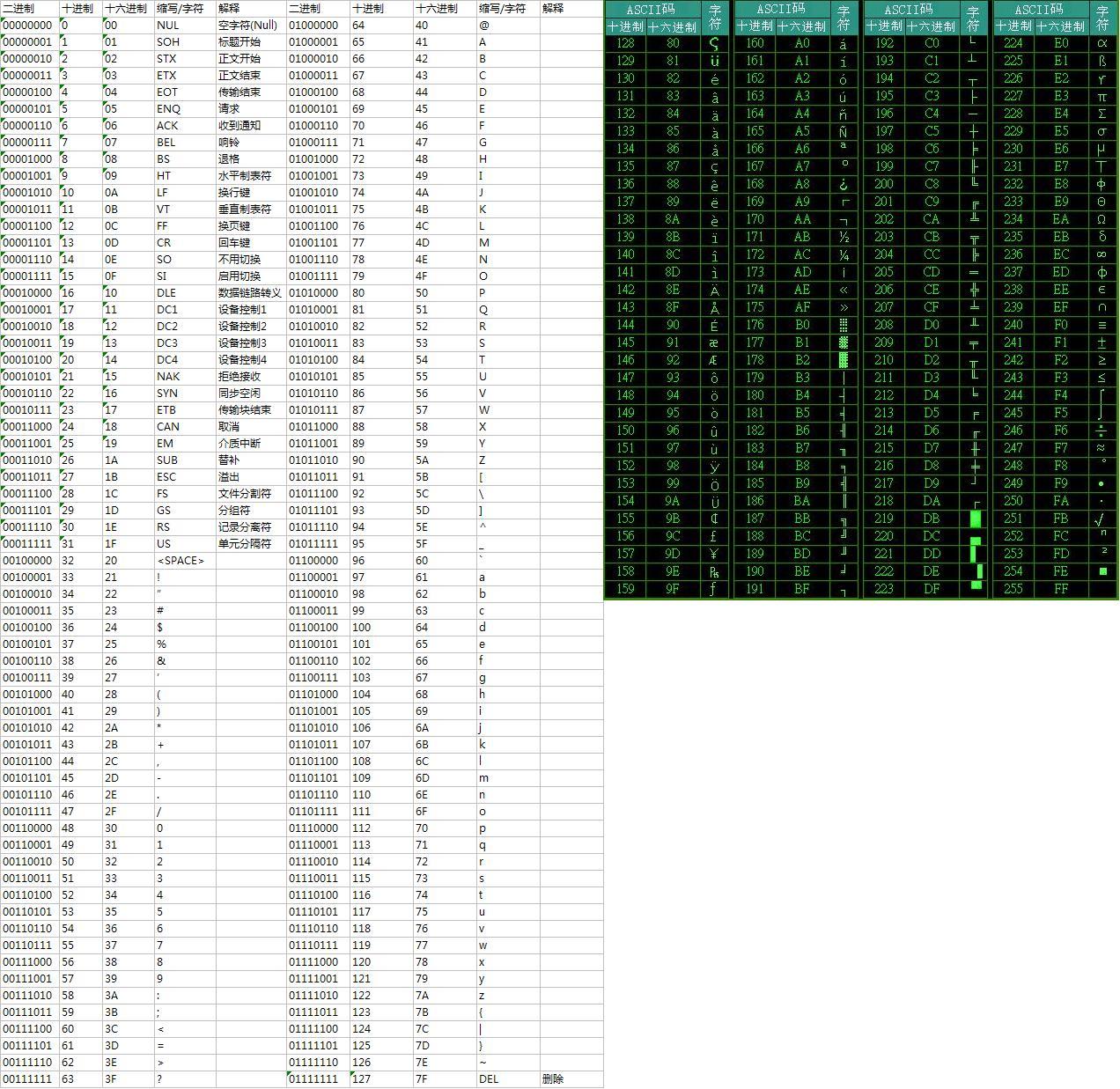
关于ASCII码的更详细介绍,可以参考ASCII
二、ISO-8859-1
ISO-8859-1编码也是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。
ISO-8859-1收录的字符除ASCII收录的字符外,还包括西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号。欧元符号出现的比较晚,没有被收录在ISO-8859-1当中。
因为ISO-8859-1编码范围使用了单字节内的所有空间,在支持ISO-8859-1的系统中传输和存储其他任何编码的字节流都不会被抛弃。换言之,把其他任何编码的字节流当作ISO-8859-1编码看待都没有问题。[重要!!]这是个很重要的特性,MySQL数据库默认编码是Latin1就是利用了这个特性。ASCII编码是一个7位的容器,ISO-8859-1编码是一个8位的容器。
Latin1是ISO-8859-1的别名,有些环境下写作Latin-1。
三、汉字编码
ASCII编码虽然能够很好的解决英文编码,却无法容纳其他的字符,特别如东南亚地区的中文、韩文等文字。为了为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的BIG5。
1.GB2312
GB2312又称为GB2312-80字符集,全称为《信息交换用汉字编码字符集?基本集》,由原中国国家标准总局发布,1981年5月1日实施。 GB2312是中国国家标准的简体中文字符集。它所收录的汉字已经覆盖99.75%的使用频率,基本满足了汉字的计算机处理需要。在中国大陆和新加坡获广泛使用。
GB2312收录简化汉字及一般符号、序号、数字、拉丁字母、日文假名、希腊字母、俄文字母、汉语拼音符号、汉语注音字母,共 7445 个图形字符。其中包括6763个汉字,其中一级汉字3755个,二级汉字3008个;包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
2.BIG5
BIG5又称大五码或五大码,1984年由台湾财团法人信息工业策进会和五间软件公司宏? (Acer)、神通 (MiTAC)、佳佳、零壹 (Zero One)、大众 (FIC)创立,故称大五码。
Big5码的产生,是因为当时台湾不同厂商各自推出不同的编码,如倚天码、IBM PS55、王安码等,彼此不能兼容;另一方面,台湾政府当时尚未推出官方的汉字编码,而中国大陆的GB2312编码亦未有收录繁体中文字。
Big5字符集共收录13,053个中文字,该字符集在中国台湾使用。耐人寻味的是该字符集重复地收录了两个相同的字:“兀”(0xA461及0xC94A)、“?”(0xDCD1及0xDDFC)。
尽管Big5码内包含一万多个字符,但是没有考虑社会上流通的人名、地名用字、方言用字、化学及生物科等用字,没有包含日文平假名及片假名字母。例如台湾视“着”为“著”的异体字,故没有收录“着”字。康熙字典中的一些部首用字(如“亠”、“疒”、“?”、“?”等)、常见的人名用字(如“?”、“煊”、“?”、“?”等) 也没有收录到Big5之中。
3.GBK
GB2312支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。
GBK编码是GB2312编码的超集,向下完全兼容GB2312,同时GBK收录了Unicode基本多文种平面中的所有CJK汉字。同 GB2312一样,GBK也支持希腊字母、日文假名字母、俄语字母等字符,但不支持韩语中的表音字符(非汉字字符)。GBK还收录了GB2312不包含的 汉字部首符号、竖排标点符号等字符。
4.GB18030
GB18030的全称是GB18030-2000《信息交换用汉字编码字符集基本集的扩充》,是我国政府于2000年3月17日发布的新的汉字编码国家标准,2001年8月31日后在中国市场上发布的软件必须符合本标准。
GB18030编码向下兼容GBK和GB2312。
GB18030字符集标准的出台经过广泛参与和论证,来自国内外知名信息技术行业的公司,信息产业部和原国家质量技术监督局联合实施。
GB18030字符集标准解决汉字、日文假名、朝鲜语和中国少数民族文字组成的大字符集计算机编码问题。该标准的字符总编码空间超过150万个编码位,收录了27484个汉字,覆盖中文、日文、朝鲜语和中国少数民族文字。满足中国大陆、香港、台湾、日本和韩国等东亚地区信息交换多文种、大字量、多用途、统一编码格式的要求。并且与Unicode 3.0版本兼容,填补Unicode扩展字符字汇“统一汉字扩展A”的内容。
该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符(就是Ext-A部分),普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
三、UNICODE
为了容纳全世界各种语言的所有字符和符号,解决不同编码之间的兼容和转换问题,1991年元月,10多家公司共同出资,组建Unicode协会,随后Unicode编码产生了。Unicode协会的口号是: 给每个字符提供了一个唯一的数字,不论是什么平台,不论是什么程序,不论什么语言。具体可以参考Unicode官方站点:www.unicode.org。
Unicode的学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。UCS可以看作是"Unicode Character Set"的缩写。
历史上存在两个试图独立设计Unicode的组织,即国际标准化组织(ISO)和一个软件制造商的协会(unicode.org)。ISO开发了ISO10646项目,Unicode协会开发了Unicode项目。在1991年前后,双方都认识到世界不需要两个不兼容的字符集。于是它们开始合并双方的工作成果,并为创立一个单一编码表而协同工作。从Unicode2.0开始,Unicode项目采用了与ISO 10646-1相同的字库和字码。
目前两个项目仍都存在,并独立地公布各自的标准。Unicode协会现在的最新版本是Unicode 5.1(2008.04.04)。ISO的最新标准是10646-3:2003。
UCS规定了怎么用多个字节表示各种文字。UCS字符集为每个字符分配了一个位置,通常用“U”再加上某个字符在UCS中位置的16进制数作为这个字符的UCS表示,例如“U+0041”表示字符“A”。
Unicode编码方案主要有三个实施标准:
UTF-8
UCS-2
UTF-16
UTF即Unicode Translation Format,即把Unicode转做某种格式的意思,可以理解为UCS字符集(或者说是Unicode字符集)实际应用中的具体编码方式。常见的UTF规范包括UTF-8、UTF-7、UTF-16。
UTF8是把ucs2(2字节unicode)按照规则转换为字节流的编码,出发点是兼容已有的各种系统。UTF-8便于不同的计算机之间使用网络传输不同语言和编码的文字,使得双字节的Unicode能够在现存的处理单字节的系统上正确传输。
UTF-8使用可变长度字节来储存 Unicode字符,例如ASCII字母继续使用1字节储存,重音文字、希腊字母或西里尔字母等使用2字节来储存,而常用的汉字就要使用3字节。辅助平面字符则使用4字节。
UTF-8完全和ASCII兼容,在UTF-8的编码的传输过程中即使丢掉一个字节,根据编码规律也很容易定位丢掉的位置,不会影响到其他字符。在其他双字节编码中,一旦损失一个字节,就会影响到此字节之后的所有字符。从这点可以看出UTF-8编码非常适合作为传输编码。
四、其他
从ASCII、GB2312、GBK到GB18030的编码方法是向下兼容的。而Unicode只与ASCII兼容(更准确地说,是与ISO-8859-1兼容),与GB码不兼容。例如“汉”字的Unicode编码是6C49,而GB码是BABA。
GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。因为兼容ASCII,在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。
在DBCS中,GB内码的存储格式始终是big endian,即高位在前。GB2312的两个字节的最高位都是1。但符合这个条件的码位只有128*128=16384个。所以GBK和GB18030的低字节最高位都可能不是1。不过这不影响DBCS字符流的解析:在读取DBCS字符流时,只要遇到高位为1的字节,就可以将下两个字节作为一个双字节编码,而不用管低字节的高位是什么。
只有编码还不够,要想显示,就需要字体文件。O是TTF的进化版本。可以认为主要是两部分:map表和图形。map表两个域:编码值和图形序号。就是读入一个编码,找到对应的图形,显示出来。字体文件可以采用gb2312,gbk和unicode等编码,现在xp系统自带凡是O的字体都是unicode,仿宋是GB2312的,幼圆是unicode。
关于各种编码的技术特征,可以参考参考资料[4]
五、参考资料
[1].中文字符集与字符编码的基础知识
[2].中文 字符集 编码 字体文件 TTF unicode
[3].汉字编码常识
[4].常用字符集编码的概要特性
[5].“GB,GBK,GB18030,Unicode”汉字编码知识
[6].ASCII:美国标准信息交换标准码
[7].UNICODE
 浙公网安备33010802004887号
浙公网安备33010802004887号